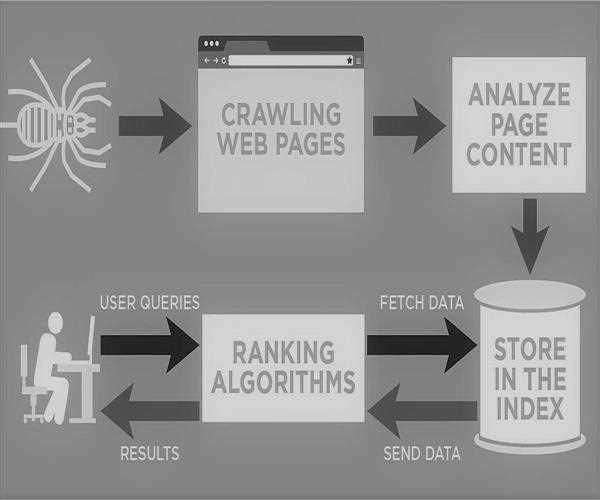
1) Crawling
Where the web crawler, or what those in the SEO world call spiders or bots, is an automated program that follows
Google’s algorithm to examine the content and structure of pages.
And Google wants you to include the following information for it to easier understand your content; title tags, Meta descriptions, headings, content, and more.
That is the reason for this is so that the bots can interpret the content, categories, and products within a page.
These are different strategies that can be placed within the code to make sure that the bots are able to crawl a page in the most effectively and efficiently.
- Create a sitemap – holds a complete list of a website’s pages and primarily lets bots know what to crawl
- Add Schema – a “roadmap” for the bots to crawl a page productively
- Disallow content within the Robots.txt file that isn’t necessary to search
- Site speed – if a page loads too slow the robot will leave before it can crawl the full page

2) Indexing
So far I have understood Google's indexing concept is that the google search index is a database that stores billions of web pages.
The
Google search index mobilizes the content within the web that has been crawled, which can be easier described as a library for Google.
If an Internet user writes a query, google searches the index to find the most relevant and applicable pages for the user.
If the crawlers find a web page they render the content. And the webpages are then indexed into Google searches database.
In to the below are a few ways to ensure that your pages are getting indexed
- Submitting a sitemap to Google Search Console – a way to help search engines perceive your website
- Submitting pages for indexing to Google Search Console – tells Google you have updated content. Google likes updated content
- Create a blog – websites with blogs get indexed more


Leave a Comment