
6 Reasons Why Java Developers Should Learn Hadoop
Want to learn Hadoop and Data science

Skills that matter- Hadoop
The world around us is changing. Traditional approaches of doing business are giving way to modern methods. Most of the transactions that take place today are over the internet and ecommerce has slowly risen to prominence.

How Open Source Big Data is driving the Global Market?
It has become a known fact that big data has been hogging the limelight in many sectors in the recent times.
Pig Latin Operators in Hadoop
Pig Latin has a simple syntax with powerful semantics we will use to carry out two primary operations:
Hadoop integration with R
Developers and Programmers are still continue to explore various approaches to leverage the distributed computation benefits of MapReduce and the almost limitless storage capabilities of HDFS in intuitive manner that can be exploited by R.
Pig Architecture and Application Flow in Hadoop
Simple” often sense as “elegant” when it comes to those remarkable architectural drawings for that new Silicon Valley mansion we have planned for when the money starts rolling in after we implement Hadoop.
MapReduce Mapper Class:
Mapper class is responsible for providing implementations for mapping jobs in MapReduce.
Managing files with Hadoop File System Commands
HDFS is one of the two main components of the Hadoop framework; the other is the computational paradigm known as MapReduce.
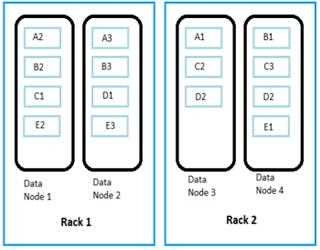
Data Replication in Hadoop: Replicating Data Blocks (Part – 1)
In HDFS, the Data block size needs to be large enough to warrant the resources dedicated to an individual unit of data processing On the other hand.
Hadoop Java API for MapReduce
Hadoop has gone through some big API change in its 0.20 release, which is the basic interface in the 1.0 version .
Input Splits and Key-Value Terminologies for MapReduce
As we already know that in Hadoop, files are composed of individual records, which are ultimately processed one-by-one by mapper tasks.
Concept of Data compression in Hadoop
The massive data volumes that are very command in a typical Hadoop deployment make compression a necessity.