Previously, we have seen RegionServers and learn how regions work. Now here
we examine comp actions.
Compaction, the process by which HBase cleans up after itself, comes and occur in two different ways:
· Major Compaction
· Minor Compaction
Major compactions can be a big deal so we’ll discuss managing them in detail in a bit, but first we need to understand minor compactions. Refer following table for illustrations:
Row Key | Column Family :{Column Qualifier: Version: Value} |
001 | CustomerName: { ‘FN’: 1383859182496:‘Sheldon’, ‘LN’: 1383859182858:’Cooper’, ‘MN’: 1383859183001:’Wills’, ‘MN’: 1383859182915:’W’} ContactInfo: {‘EA’: 1383859183030:‘sh.cooper@mindstick.com’, ’SA’: 1383859183073: ’45 LT NY’} |
002 | CustomerName: {‘FN’: 1383859183103:‘Hank’, ‘LN’: 1383859183163:‘Moody’, ContactInfo: { ’SA’: 1383859185577: ‘16 TL CA’} |
Minor Compactions
Minor compactions combine together a configurable number of smaller HFiles into a single larger HFile. We can manipulate the number of HFiles to compact and also the frequency of a minor compaction. Minor compactions are very crucial because without them, reading a individual row can need many disk reads and cause slow overall performance. Adjoining figure, which illustrates how this concept works, can help us visualize how data table can be persisted on the HDFS.
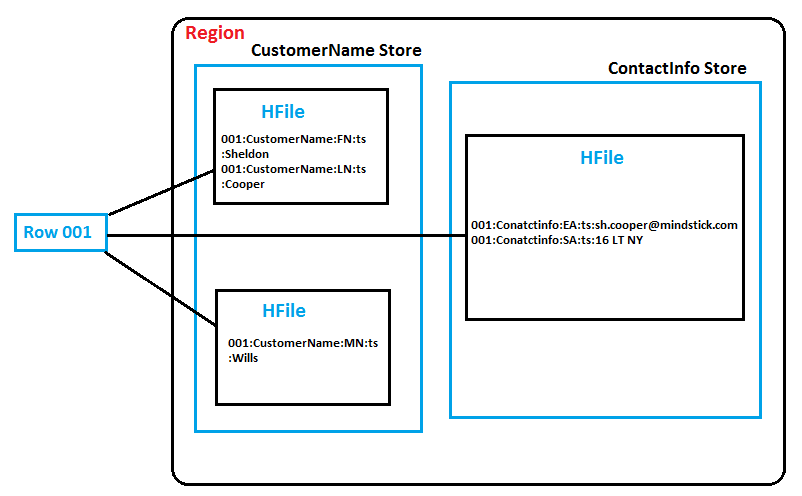
Looking at the adjoining figure and observe how the CustomerName column family was written to the HDFS with two MemStore flushes and also how the data in the Contact Info column family was persisted to disk with only single MemStore flush. This illustration is hypothetical, but it’s a very favorable scenario which depends on the timing of the writes. Imagine a software service provider company like Mindstick that’s gaining more and more client contact information over time. The company may know its customer’s first and last name but not learn about its middle name until hours or weeks later in subsequent service requests. This scenario would result in parts of Row 001 being persisted to the HDFS in different HFiles. Until the HBase system performs a minor compaction, reading from Row 001 would require three disk reads to retrieve the relevant HFile content! Minor compactions enables to minimize system overhead by keeping the number of HFiles under control. HBase designers took special care to give the HBase DBA’s as much tuning control as possible to make any system impact “minor.”
Major Compactions
As its name suggests, a major compaction is quite different from the perspective of a system impact. However, the compaction is quite crucial to the overall functionality of the HBase system. A major compaction enable us to combine all HFiles into one large HFile. In addition, a major compaction does the clean-up work after a user deletes a record. When a user commands for a Delete call, the HBase system locates and places a marker in the key-value pair so that it can be permanently removed from the disk during the next major compaction. Additionally, because major compactions combine all HFiles into one large HFile, the time is correct for the system to review the versions of the data and compare them against the time to live (TTL) property. Values older than the TTL are always purged.
Time to live refers to the variable in HBase, which we can set in order to define how long data with multiple versions will remain in HBase.
We may have guessed that a major compaction significantly affects the system response time. Developers who are trying to add, retrieve or manipulate data in the system during a major compaction, they may see poor system response time. In addition, the HBase cluster may have to split regions at the same time that a major compaction is taking place and balance the regions across all RegionServers. This situation would result in an awful amount of network traffic between RegionServers. For these reasons, our HBase DBA needs to have a major compaction strategy for our deployment.

Simond Gear
31-Mar-2017