tag
home / developersection / tag

Ways Big Data is Changing The business
Go deep into the exciting world of big data and its applications in various industries to give your mind a dose of knowledge.
Why learn Hadoop & big data technology in 2019?
There is a huge amount of data floating around the web and this is why big data analytics is considered important in improving the decision-making pro
What is the future of Big Data in Real Estate Sector?
Big Data technologies are being used by almost every industry and its adoption is increasing day by day. This article is to discuss the effect of Big Data on the real estate sector or to discuss how Big Data is affecting the real estate.
A General Overview on Growing Hadoop Developer Jobs in the USA
You have taken your much-needed Hadoop training, you now know a considerable measure about Big Data, and you have contributed hours, days and long per
Huge job options are the reason why big data is the best career move in 2018 across different indust
Big data analytics and meaningful insights have transformed the businesses and driving growth. According to a survey, there is more than 3 million jobs are predicted by the end of 2020.
The Popularity of Big Data Hadoop Certification in 2018
With the warn adoption of Hadoop platform, it is expected that more than 50 percent of data will be processed by big data platform by the end of the year 2020. So, demand for Hadoop professionals is actually very high, you can think of.

Data Science Analytics Certification for Data Governance
Data governance becomes very important in such scenarios. What’s data governance? It’s the complete administration of usability, integrity, availability, and data security in an organization.
HDFS vs. HBase : All you need to know
It has created the need for a more organized file system for storage and processing of data, when it is observed a sudden increase in the volume of data from the order of gigabytes to zettabytes.
Switching from Java to Big Data/Hadoop Career: The Whys and Hows
Once in a while, there may come a feeling that you are stuck in the same job profile and living a monotonous professional life. This generally leads to the realization that a change in your profile is much needed.
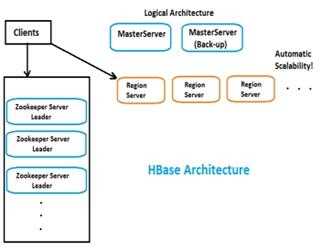
HBase Architecture: Introduction and RegionServers(Part-1)
The reason that folks such as chief financial officers are excited by the thought of using Hadoop is that it lets us store massive amounts of data across a cluster of low cost commodity servers — that’s music to the ears of financially minded people.
Big Data: HBase as Distributed, Persistent, Multidimensional Sorted Map
Now we are very well familiar with the power packed characteristics and nature of Hbase. As we define already Hbase is a big data tool (used by Hadoop
Pig Script Interfaces and Mode of Running in Hadoop
Local and Distributed Modes of Running Pig ScriptPig has two modes for running scripts: Local Mode and MapReduce Mode:Local mode:All scripts are run o