Introduction to Ooize in Hadoop
Moving data and running different kinds of applications in Hadoop is great stuff, but it’s only half the battle. For Hadoop’s efficiencies to truly st
Clustering and Classification with Mahout
Unlike the supervised learning method described earlier for Mahout’s recommendation engine feature, clustering is a kind of unsupervised learning — where the data labels points are not known ahead of time and should be inferred from the data without
Statistical Analysis in Hadoop
Big data is all about applying analytics to more data, for more people. To carry out this task, big data practitioners use new tools — such as Hadoop
MapReduce Driver Class:
Although the mapper and reducer implementations are all we need to perform the MapReduce job, there is one more piece of code necessary in MapReduce:
Pig Data Types in Hadoop
We have already seen the Pig architecture and Pig Latin Application flow. We also learn the Pig Design principle in the previous post. Now it’s time t
Pig Design Principles in Hadoop
Pig Latin is the programing platform which provides a language for Pig programs. Pig helps to convert the Pig Latin script into MapReduce tasks that can be run within Hadoop cluster.
Introduction to Pig in Hadoop
Java MapReduce programs and the Hadoop Distributed File System (HDFS) provide us with a powerful distributed computing framework, but they come with one major drawback
YARN’s Resource Management
Yarn’s Resource ManagerThe most key component of YARN is the Resource Manager, which governs and maintains all the data processing resources in the Ha
Hadoop File System Commands: ls Command Output Analysis
In my previous post, I have explained various Hadoop file system commands, in which I also explained about the “ls command”. I have written the syntax
HDFS Architecture in Hadoop
The core concept of HDFS is that it can be made up of dozens, hundreds, or even thousands of individual computers, where the system’s files are stored in directly attached disk drives.
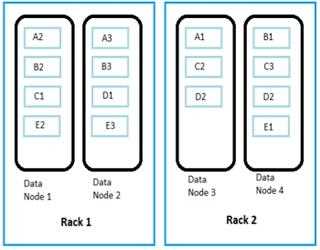
Data Replication in Hadoop: Slave node disk failures (Part -2)
In Part -1, I explained about Data Replication in Hadoop: Replicating Data Blocks (Part – 1) now in this post I am trying to explain about Slave node
Three modes of Hadoop Cluster Architecture
Hadoop is primarily structured and designed to be deployed on a massive cluster of networked systems or nodes, featuring master nodes (which host the