Why we need Map-Reduce in Hadoop?
After we have stored piles and piles of data in HDFS (a distributed storage system spread over an expandable cluster of individual slave nodes), the f
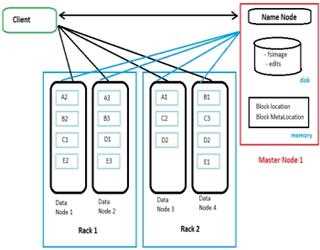
Writing and Reading Data from HDFS
Writing dataFor creating new files in HDFS, a set of process would have to take place (refer to adjoining figure to see the components involved):1.The
HDFS Federation and High availability
Before Hadoop 2 comes to the picture, Hadoop clusters were living with the fact that Name Node has placed limits on the degree to which they could scale.
Various Data compression codecs in Hadoop
Here we enlist and identify some common codecs that are supported by the Hadoop framework. Be sure to opt for the codec that most closely matches the
Storing Data in HDFS
Just to be clear, storing data in HDFS is not entirely the same as saving files on your personal computer. In fact, quite a number of differences exis
Hadoop Toolbox
Besides, the major contribution of Amazon EMR services and its other related tools, many other companies also provide certain useful Hadoop Tools enlisted as following:
Concept of Map Reduce in Hadoop
Though MapReduce as a technology is relatively new, it builds upon much of the fundamental work from both mathematics and computer science, particular
Hadoop Distributions: EMC, HotonWork and MapR
Besides Cloudera, there are few other popular Hadoop distribution which are well implemented for commercial and development purposes.EMC: Pivotal HD,
Hadoop Distributions: Cloudera
We have seen that the Hadoop ecosystem has several component parts, all of which exist as their own Apache projects. Since Hadoop has become extremely
Hadoop Distributed processing with MapReduce
MapReduce comprises the sequential processing of operations on distributed volumes of data sets. The data comprises of key-value pairs, and the overal
Pros and Cons of Hadoop System
As with any tool, it's important to understand when Hadoop is a good fit for the problem in question. The architecture choices made within Hadoop enab
Graph Analysis with Hadoop
We all are already familiar with log data, relational data, text data, and binary data, but we will soon hear about another form of information: graph data.