Managing files with Hadoop File System Commands
HDFS is one of the two main components of the Hadoop framework; the other is the computational paradigm known as MapReduce.
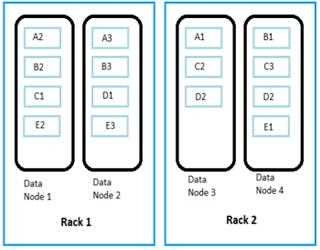
Data Replication in Hadoop: Replicating Data Blocks (Part – 1)
In HDFS, the Data block size needs to be large enough to warrant the resources dedicated to an individual unit of data processing On the other hand.
Hadoop Java API for MapReduce
Hadoop has gone through some big API change in its 0.20 release, which is the basic interface in the 1.0 version .
Input Splits and Key-Value Terminologies for MapReduce
As we already know that in Hadoop, files are composed of individual records, which are ultimately processed one-by-one by mapper tasks.
Log Data Ingestion with Flume
Some amount of data volume that ends up in HDFS might land there through database load operations or other types of batch processes.
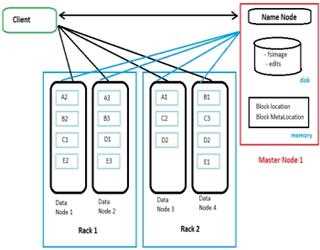
Name Node Design and its working in HDFS
Whenever a user tries to stores a file in HDFS, the file is first break down into data blocks, and three replicas of these data blocks are stored in slave nodes (data nodes) throughout the Hadoop cluster
Check pointing process in HDFS
As we already know now that HDFS is a journaled file system, where new changes to files in HDFS are captured in an edit log that’s stored on the NameNode in a file named edits.
Concept of Data compression in Hadoop
The massive data volumes that are very command in a typical Hadoop deployment make compression a necessity.
Importance of Map Reduce in Hadoop
From the beginning of the Hadoop’s history, MapReduce has been the complete game changer in town when it comes to deal with data processing.
Slave Node Server Design for HDFS
When we are choosing storage options, consider the impact of using commodity drives rather than more expensive enterprise-quality drives.
How to Choose the Right Hadoop Distribution?
Commercially available distributions of Hadoop offer different combinations of open source components from the Apache Software Foundation and from several other places
Hadoop Tools: Amazon Services
A number of companies offer tools designed to help you get the most out of your Hadoop implementation. Here’s a sampling: