category
home / developersection / category
HBase Data Model: Row Keys and Column Families (Part – 1)
HBase data stores comprises of one or more tables, that are indexed by row keys. Data is stored in rows with columns, and rows can have multiple versions.
Big Data: What is Sparse Data in HBase?
As we might have guessed, the Google’s BigTable distributed data storage system(DDSS) was designed to meet the demands of big data. Now, big data applications store massive amount of data but big data content is also often variable.
Big Data: Evolution of HBase
I think everybody remember his first surfing experience on the World Wide Web,; we just knew that it was an incredible innovation for the IT industry.
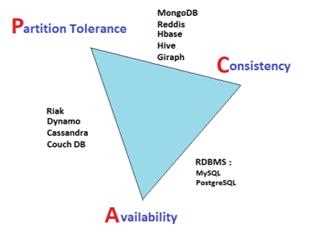
Big Data: CAP Theorem
Selecting a database which fits in our application requirement is a very daunting task since “no one size fits all”.
Big Data: NoSQL Data Stores
NoSQL database stores are initially considering the notion “Just Say No to SQL” and these were the reactions to the perceived limitations of (SQL-based) relational databases RDBMS.
Machine Learning with Mahout and Collaborative Filtering
Machine learning refers to a feild of artificial intelligence (A.I.) functions that provides tools enabling computers to enhance their analysis on the basis of previous events.
MapReduce Reducer Class:
MapReduce API has two main classes which do the Map-Reduce task for us: Mapper class and Reducer class.
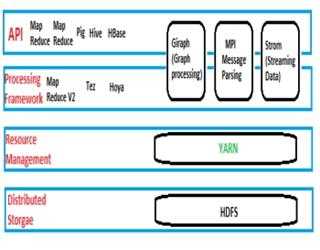
YARN: Yet Another Resource Negotiator
With the release of Hadoop 2, however, YARN was introduced, which open doors for whole new world of data processing opportunities.
Log Data Ingestion with Flume
Some amount of data volume that ends up in HDFS might land there through database load operations or other types of batch processes.
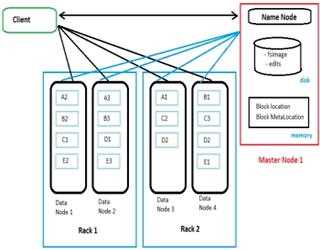
Name Node Design and its working in HDFS
Whenever a user tries to stores a file in HDFS, the file is first break down into data blocks, and three replicas of these data blocks are stored in slave nodes (data nodes) throughout the Hadoop cluster
Check pointing process in HDFS
As we already know now that HDFS is a journaled file system, where new changes to files in HDFS are captured in an edit log that’s stored on the NameNode in a file named edits.
Slave Node Server Design for HDFS
When we are choosing storage options, consider the impact of using commodity drives rather than more expensive enterprise-quality drives.