
3 Pillars of the Data Economy
Our industry continues to see an ongoing upsurge in data volumes. This comes with the insatiable need by industry-leading companies to exploit existing data to foster business development and growth.
Analytics Bots: What Are They and How Do They Work?
In media, the word “bot” tends to bring to mind a twitter account run by a computer program that spits out mostly nonsensical tweets at other users. Generating basic language may not seem like a big deal,...

How You Can Use Data to Improve the Customer Experience
When you want to improve user experience with your product, or when you want to improve customer experience with your service, how do you go about doing it?

Three Ways AI Will Change IT Operations and Data Center Management
Artificial Intelligence, and machine learning in particular, is predicted to have an enormous impact on many industries over the next few years, not least the industry that builds and manages the infrastructure on which machine learning algorithms...

What is the Impact of Big Data on Mobile Marketing?
Every business in one way or the other has access to data corresponding to their customers, competition, and market. Naturally, to stand out from other businesses and to ensure competitive advantage they need insights from other areas.

Big Data In Banking: Advantages and Challenges
Because of the confidential nature of data in banking services, most of the financial institutions have been slow in adapting to big data even though they do realize that there are huge benefits in terms of customer centricity.

Big Data Analytics
Big data analytics is the process of inspecting large and different data sets i.e., big data – to discover hidden patterns, market trends, unknown correlations, customer preferences and other useful information that can help organizations.
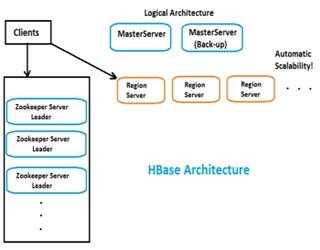
HBase Architecture: Introduction and RegionServers(Part-1)
The reason that folks such as chief financial officers are excited by the thought of using Hadoop is that it lets us store massive amounts of data across a cluster of low cost commodity servers — that’s music to the ears of financially minded people.
Big Data: HBase as Distributed, Persistent, Multidimensional Sorted Map
Now we are very well familiar with the power packed characteristics and nature of Hbase. As we define already Hbase is a big data tool (used by Hadoop
Big Data: ACID versus BASE Data Stores
I think back in our school days, almost all of us have studied about difference between ACID” and “BASE in chemistry. There we use to distinguish betw
Clustering and Classification with Mahout
Unlike the supervised learning method described earlier for Mahout’s recommendation engine feature, clustering is a kind of unsupervised learning — where the data labels points are not known ahead of time and should be inferred from the data without
MapReduce Driver Class:
Although the mapper and reducer implementations are all we need to perform the MapReduce job, there is one more piece of code necessary in MapReduce: