For a long time, software deployment meant one thing: get the code onto the server. That was the whole job. Write the code, package it, transfer it to the production environment, restart the service, and hope. If it worked, great. If it did not, you figured out why and tried again. The deployment was successful the moment the service came back up and responded to requests.
That definition does not hold anymore. Teams that treat deployment as a solved problem the moment code reaches production are working with a mental model that does not match the complexity of modern systems. The code arriving in production is the beginning of a deployment, not the end.
What modern software deployment actually requires goes well beyond the mechanics of transferring code. Understanding what has changed and what the full picture looks like is worth the time for any team that ships software regularly.
The Gap Between Code in Production and Software Working Correctly
There is a gap between code being in production and software actually working correctly. It sounds obvious when stated directly. In practice most teams behave as though the gap does not exist or is someone else's problem to close.
The gap exists because modern systems are not monoliths that can be fully understood from a single deployment event. They are collections of services that communicate with each other, depend on each other, and change on independent schedules. When service A deploys a new version, the question of whether the deployment succeeded is not just about whether service A's new code is running. It is about whether service A's new code is working correctly with service B, service C, and every other service it communicates with.
Closing this gap requires three things that the traditional definition of deployment did not include: validation before the switch, observation after the switch, and the ability to reverse course quickly when something unexpected surfaces.
Validation Before the Traffic Switch
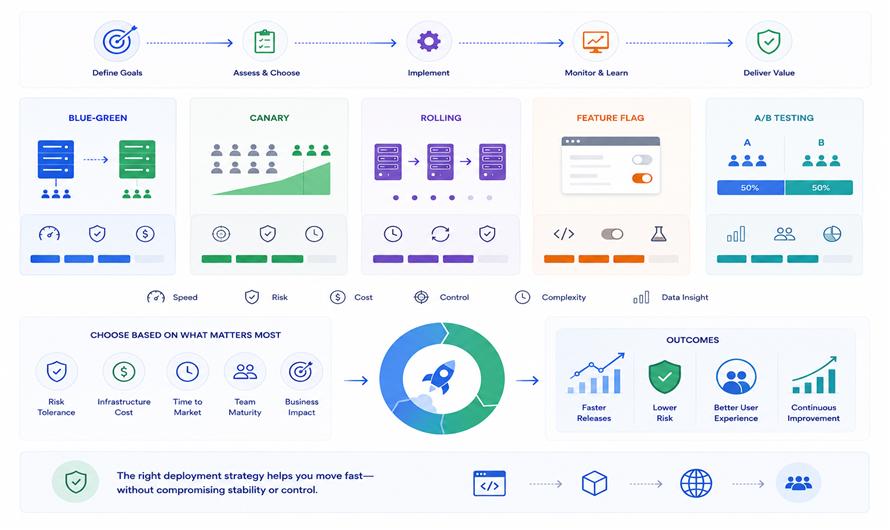
The software deployment strategies that modern teams use: blue-green deployments, canary releases, rolling updates - all share a common structure. The new version of the code gets deployed to an environment that is not yet serving production traffic. It gets validated there. Then traffic gets switched.
The validation step is where the real work happens. Running the new version in a staging-like state before exposing it to users gives teams a window to catch failures that made it past the test suite. Integration failures that only appear when real downstream services are involved. Configuration differences between environments that affect behavior. Startup issues that only manifest under production load.
What teams validate during this window varies significantly. Teams that take it seriously run behavioral validation against the idle environment - not just health checks that confirm the service is responding, but checks that confirm the service is responding correctly. Does the authentication flow still work? Do the API endpoints return the expected shapes? Do the integrations with downstream services behave as expected?
This is where automated API testing becomes genuinely valuable in the deployment process rather than just in the development process. Tools that can replay captured real traffic against a new version of a service and flag behavioral divergences give teams a way to validate that the new version behaves like the old one before it sees real users. Keploy does this specifically - capturing real API traffic from running services and using those interactions to validate new versions before deployment, which turns the pre-switch validation window from a manual check into a systematic process.
Observation After the Traffic Switch
Getting traffic onto the new version is not the end of the deployment. It is the beginning of the observation period.
Modern deployments treat the period immediately after a traffic switch as an active monitoring window rather than a passive waiting period. Error rates, latency percentiles, downstream service behavior, business metric trends - these need to be watched in real time, not reviewed in a post-mortem after something breaks.
The observation period has a defined scope. How long does the team watch before declaring the deployment successful? What metrics does a successful deployment need to maintain? What thresholds trigger an investigation before they trigger a rollback?
Teams that answer these questions before each deployment - rather than improvising after something looks wrong - consistently handle deployment incidents faster and with less collateral damage than teams that do not. The definition of success is established when there is still time to think clearly, not when an alarm is firing, and everyone is scrambling.
Rollback as a First-Class Capability
Most teams have a theoretical rollback capability. Fewer have practiced one.
The difference matters enormously when something actually goes wrong in production. A rollback process that has never been rehearsed will encounter friction at the worst possible moment - when a production incident is ongoing and every minute of degraded service is costing the team. Config files that need manual updates, DNS changes that take longer than expected, deployment artifacts that were not retained - these problems are entirely preventable but only if rollback is treated as a capability that needs to be maintained, not a hypothetical option that will work when needed.
Teams that deploy with genuine confidence have typically validated their rollback process in a non-emergency context. They have deliberately deployed a version with a known issue to a staging environment and practiced the full rollback sequence. They know how long it takes. They know where the friction points are. They have removed the friction points that can be removed in advance.
This practice sounds like overkill until the first time a production incident requires a rollback that goes smoothly because the team has done it before.
Feature Flags as Part of the Deployment Architecture
One of the most significant shifts in how modern software deployment works is the decoupling of deployment from release through feature flags.
Deploying code and releasing a feature used to be the same event. Code went to production, and users saw the change. Feature flags separate these two events. Code can deploy to production in a disabled state - fully shipped, not yet visible to users. The feature becomes visible when the flag is turned on, which can happen independently of any further deployment.
This changes the risk profile of deployments significantly. A deployment that contains disabled code carries less risk than a deployment that contains active changes visible to all users. If something goes wrong after a deployment, the team can turn off the relevant flag without needing a full rollback. If a feature needs to be rolled back to a specific user segment, the flag makes that possible without a deployment event.
Feature flags add operational complexity - flag states need to be managed, old flag logic needs to be cleaned up, and teams need tooling to manage flags across environments. But for teams shipping significant features regularly, the decoupling of deployment from release is worth the overhead.
Deployment as a Shared Responsibility
Perhaps the most significant shift in what modern software deployment requires is organizational rather than technical. Deployment is no longer a handoff from development to operations. It is a shared responsibility that spans both.
The developer who wrote the code has context about what changed and what might behave differently. The platform team has context about the deployment infrastructure and what the healthy baseline looks like. Neither group alone has the full picture needed to make a deployment succeed.
Teams that deploy confidently tend to have practices that ensure this context gets shared at deployment time rather than reconstructed after an incident. Deployment checklists that include context from both development and operations. On-call rotations that ensure the person deploying has backup from someone who knows the infrastructure. Post-deployment communication that keeps stakeholders informed without requiring a crisis to trigger it.
What It Means for Software Deployment to Actually Succeed
A software deployment succeeds when users experience the intended change without experiencing unintended problems. That is a higher bar than code running in production. It requires validation before the switch, observation after the switch, rollback capability that has been tested, and organizational practices that share context across the people responsible for shipping.
Teams that have internalized this broader definition of software deployment ship with a different kind of confidence than teams that consider the job done when the pipeline goes green. They have closed the gap between code in production and software working correctly. They have made deployment a repeatable, well-understood process rather than a high-stakes event that creates anxiety regardless of how thoroughly the code was tested.
That is what modern software deployment actually requires.


Leave a Comment