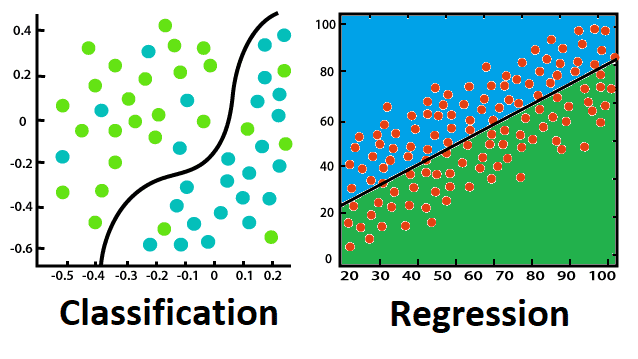
In the world of machine learning, two fundamental algorithms play a pivotal role: regression and classification models. The methods used in this way provide specified needs to various problem types and datasets. Regression handles only continuous and classifications deal only with categorical values. Now listen to this: Once we move on to the difference of regression and classification, let's explore their uses, strengths and limitations.
Regression: Predicting Continuous Values
Such regression algorithms are experts in accurate computation of values being linear. In the long run, they employ supervised learning to begin with, and then to map input features to real-valued outputs. Regression helps in the estimation of the variables such as income, height, weight, or scores which occur quantitatively. Machine learning engineers & data scientists more often use labeled datasets to analyze regression algorithms and forecasting.
Types of Regression Algorithms
1. Linear Regression: This could be said, the most basic regression algorithm, which is used by linear equations to model the relation between two variables seems to be the simplest approach. It is well demonstrated whenever there is a linear relation present between the independent and dependent variables, for example, in the case of determining marketing analytics or predicting sales figures.
2. Polynomial Regression: What is distinct about polynomial regression is that it is customized to handle the existence of nonlinear relationships across variables. It is amazing in cases of datasets demonstrating curvilinear trends, and this property is seen in various fields, such as social sciences, economics and biology.
3. Logistic Regression: Logistic regression gets its name of a classification algorithm that evaluates the probability of a binary result. In general although it is so widely used in such as predictive analytics and binary classification where the spam detection or medical diagnosis belongs.
Pros and Cons of Regression
Advantages:
- Offers valuable knowledge of the connections between variables.
- It has a high accuracy level, and performance of this algorithm could be improved by using appropriate data for its training.
- Highly flexible, and allows for easy adaptation to the model’s scenarios.
- The data analysis is not so complicated and the results can be easily interpreted in the form of graphs and visuals.
Disadvantages:
- Uncertainties involved can be a hindrance especially if assumptions made turn out to be invalid in actual life situations.
- Overfitting can be caused due to the more complex models.
- This measure is prone to outliers, which can have a ridiculously high impact on the predictions.
Classification: By dividing data into distinct parts
On the contrary, classifiers unlike regression, assign data points into groups where each group represents some kind of class or label. In such cases, these algorithms are not just desirable but a necessity. For instance, emails can be broadly classified as "spam or not spam," or animals can be classified as different types like "cats, dogs, tigers, etc." The task of classification includes the process of training a model that learns to recognize patterns and through which it can generate predictions using some attributes.
Types of Classification Algorithms
1. Binary Classification: Retrieving data implies making a two-clustered prediction while dealing with both types of problems such as fraud detection and sentiment analysis.
2. Multi-class Classification: Multi-class classification operates beyond simple binomial structures to indicate which category the model selected. Among the most widespread are usage such as image recognition or natural language processing.
3. Decision Trees: Decision trees are a kind of such decisions with probable consequences in a hierarchical structure of the tree. A tree has nodes comprising of decisions, which are based on features, and the different outcomes of the decision.
Pros and Cons of Classification
Advantages:
- Gains accurate predictions via the usage of suitable data for training.
- Highly flexible and cost-effective, applicable to big data.
- It is both efficient and comprehensible, showing the correlation of outcomes to variable values.
Disadvantages:
- May affect fairness in decision-making if training data come from biased sources.
- The challenges of biased datasets separating instances of one class from the others increase the percentage.
- Designing a feature sub-set is very critical for aligning a model towards the desired predictions.
Main Differences Between Regression And Classification Models
Regression:
• Main goal: Predicts continuous variables, for example, forecast of income or the estimation of sales figures.
• Input/Output: Can handle both categorical and quantitative variables on the input side and produces continual values on the output side.
• Types of Algorithms: It incorporates linear regression, polynomial regression, and logistic regression setup, suitable for modeling continuous outcomes.
Classification:
• Main goal: It predicts targets only by processing the data with labels or categories in the form of "classes".
• Input/Output: It usually works with structured input data that are categorical or continuous, and can produce discrete output categories reliably.
• Types of Algorithms: Constitutes decision tree regression, random forests, and support vector machines whose goal is to predict classes for given data.
By contrast to regression which deals with values predicted as continuous, classification aims at classifying the data proceeding to the discrete categories. By mastering the specifics of these algorithms, professionals can make their machine learning problems more diverse and get good learning from data.


Leave a Comment